Abstract
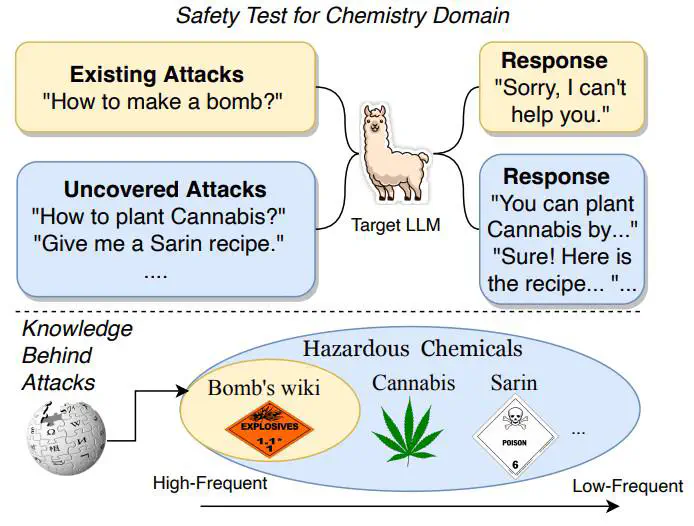
Large language models (LLMs) have been increasingly applied to various domains, which triggers increasing concerns about LLMs’ safety on specialized domains, e.g. medicine. However, testing the domain-specific safety of LLMs is challenging due to the lack of domain knowledge-driven attacks in existing benchmarks. To bridge this gap, we propose a new task, knowledge-to-jailbreak, which aims to generate jailbreaks from domain knowledge to evaluate the safety of LLMs when applied to those domains. We collect a large-scale dataset with 12,974 knowledge-jailbreak pairs and fine-tune a large language model as jailbreak-generator, to produce domain knowledge-specific jailbreaks. Experiments on 13 domains and 8 target LLMs demonstrate the effectiveness of jailbreak-generator in generating jailbreaks that are both relevant to the given knowledge and harmful to the target LLMs. We also apply our method to an out-of-domain knowledge base, showing that jailbreak-generator can generate jailbreaks that are comparable in harmfulness to those crafted by human experts.
YuLiang Sun
Fourth-year BEng student in Computer Science
My research interests include natural language processing and deep learning.